Home

![]()



![]()
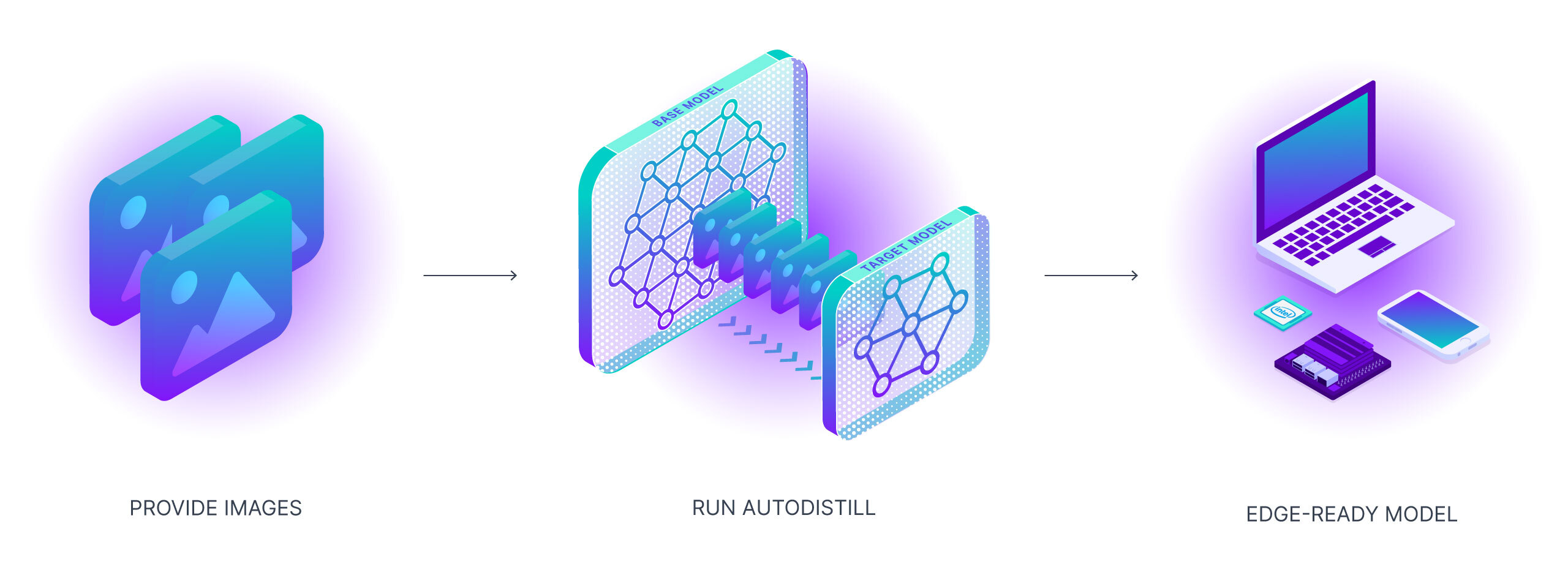
Autodistill uses big, slower foundation models to train small, faster supervised models. Using autodistill, you can go from unlabeled images to inference on a custom model running at the edge with no human intervention in between.
You can use Autodistill on your own hardware, or use the Roboflow hosted version of Autodistill to label images in the cloud.
Here are example predictions of a Target Model detecting milk bottles and bottlecaps after being trained on an auto-labeled dataset using Autodistill (see the Autodistill YouTube video for a full walkthrough):

🚀 Features¶
- 🔌 Pluggable interface to connect models together
- 🤖 Automatically label datasets
- 🐰 Train fast supervised models
- 🔒 Own your model
- 🚀 Deploy distilled models to the cloud or the edge
📚 Basic Concepts¶
To use autodistill, you input unlabeled data into a Base Model which uses an Ontology to label a Dataset that is used to train a Target Model which outputs a Distilled Model fine-tuned to perform a specific Task.

Autodistill defines several basic primitives:
- Task - A Task defines what a Target Model will predict. The Task for each component (Base Model, Ontology, and Target Model) of an
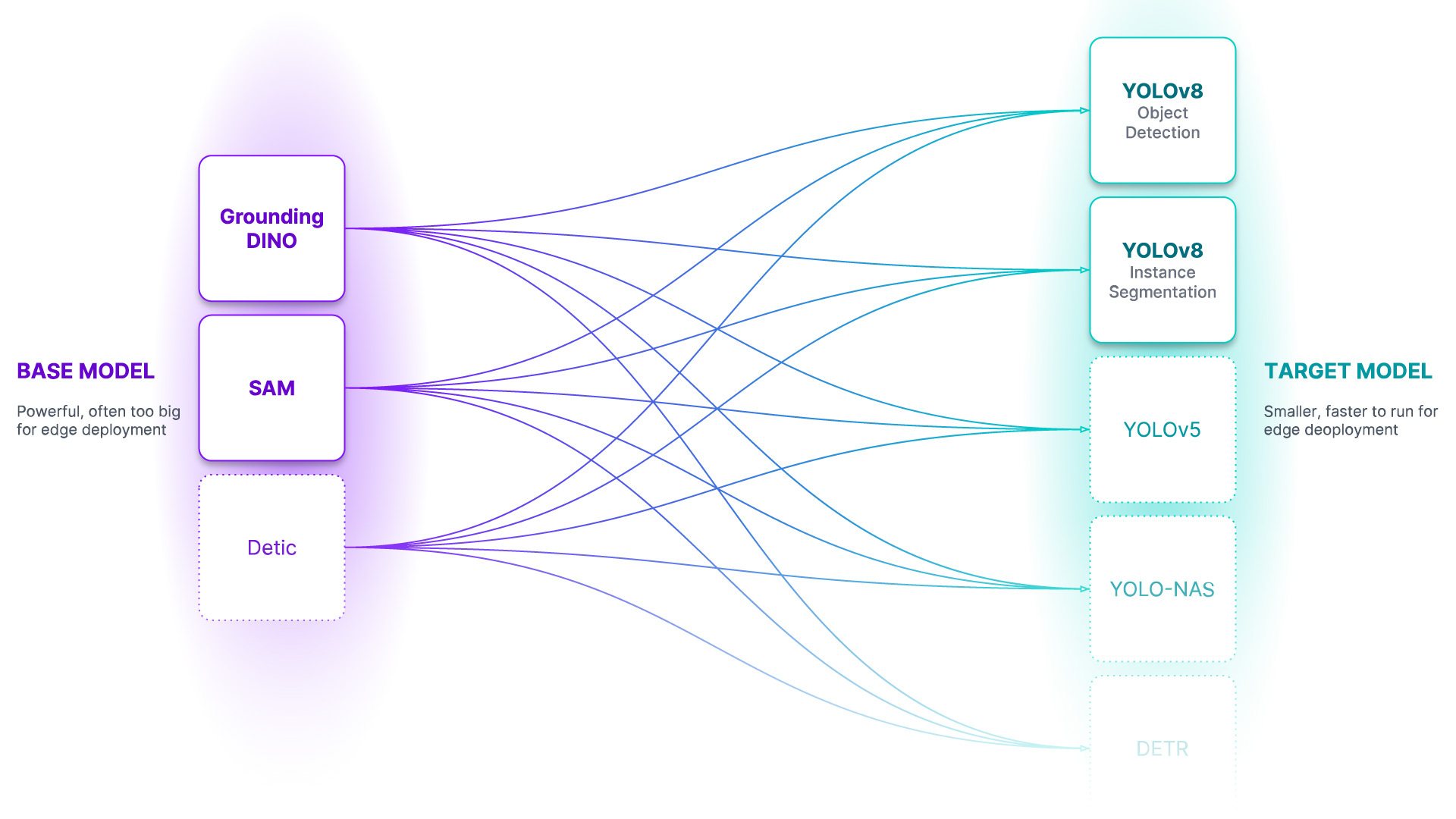
autodistillpipeline must match for them to be compatible with each other. Object Detection and Instance Segmentation are currently supported through thedetectiontask.classificationsupport will be added soon. - Base Model - A Base Model is a large foundation model that knows a lot about a lot. Base models are often multimodal and can perform many tasks. They're large, slow, and expensive. Examples of Base Models are GroundedSAM and GPT-4's upcoming multimodal variant. We use a Base Model (along with unlabeled input data and an Ontology) to create a Dataset.
- Ontology - an Ontology defines how your Base Model is prompted, what your Dataset will describe, and what your Target Model will predict. A simple Ontology is the
CaptionOntologywhich prompts a Base Model with text captions and maps them to class names. Other Ontologies may, for instance, use a CLIP vector or example images instead of a text caption. - Dataset - a Dataset is a set of auto-labeled data that can be used to train a Target Model. It is the output generated by a Base Model.
- Target Model - a Target Model is a supervised model that consumes a Dataset and outputs a distilled model that is ready for deployment. Target Models are usually small, fast, and fine-tuned to perform a specific task very well (but they don't generalize well beyond the information described in their Dataset). Examples of Target Models are YOLOv8 and DETR.
- Distilled Model - a Distilled Model is the final output of the
autodistillprocess; it's a set of weights fine-tuned for your task that can be deployed to get predictions.
💡 Theory and Limitations¶
Human labeling is one of the biggest barriers to broad adoption of computer vision. It can take thousands of hours to craft a dataset suitable for training a production model. The process of distillation for training supervised models is not new, in fact, traditional human labeling is just another form of distillation from an extremely capable Base Model (the human brain 🧠).
Foundation models know a lot about a lot, but for production we need models that know a lot about a little.
As foundation models get better and better they will increasingly be able to augment or replace humans in the labeling process. We need tools for steering, utilizing, and comparing these models. Additionally, these foundation models are big, expensive, and often gated behind private APIs. For many production use-cases, we need models that can run cheaply and in realtime at the edge.
Autodistill's Base Models can already create datasets for many common use-cases (and through creative prompting and few-shotting we can expand their utility to many more), but they're not perfect yet. There's still a lot of work to do; this is just the beginning and we'd love your help testing and expanding the capabilities of the system!
💿 Installation¶
Autodistill is modular. You'll need to install the autodistill package (which defines the interfaces for the above concepts) along with Base Model and Target Model plugins (which implement specific models).
By packaging these separately as plugins, dependency and licensing incompatibilities are minimized and new models can be implemented and maintained by anyone.
Example:
pip install autodistill autodistill-grounded-sam autodistill-yolov8
Install from source
You can also clone the project from GitHub for local development:git clone https://github.com/roboflow/autodistill
cd autodistill
pip install -e .
Additional Base and Target models are enumerated below.
🎬 Video Guides¶
 Autodistill: Train YOLOv8 with ZERO Annotations
Autodistill: Train YOLOv8 with ZERO Annotations
In this video, we will show you how to use a new library to train a YOLOv8 model to detect bottles moving on a conveyor line. Yes, that's right - zero annotation hours are required! We dive deep into Autodistill's functionality, covering topics from setting up your Python environment and preparing your images, to the thrilling automatic annotation of images.
💡 Community Resources¶
- Distill Large Vision Models into Smaller, Efficient Models with Autodistill: Announcement post with written guide on how to use Autodistill
- Comparing AI-Labeled Data to Human-Labeled Data: A qualitative evaluation of Grounding DINO used with Autodistill across various tasks and domains.
- How to Evaluate Autodistill Prompts with CVevals: Evaluate Autodistill prompts.
- Autodistill: Label and Train a Computer Vision Model in Under 20 Minutes: Building a model to detect planes in under 20 minutes.
- Comparing AI-Labeled Data to Human-Labeled Data: Explore the strengths and limitations of a base model used with Autoditsill.
- Train an Image Classification Model with No Labeling: Use Grounded SAM to automatically label images for training an Ultralytics YOLOv8 classification model.
- Train a Segmentation Model with No Labeling: Use CLIP to automatically label images for training an Ultralytics YOLOv8 segmentation model.
- File a PR to add your own resources here!
🗺️ Roadmap¶
Apart from adding new models, there are several areas we plan to explore with autodistill including:
- 💡 Ontology creation & prompt engineering
- 👩💻 Human in the loop support
- 🤔 Model evaluation
- 🔄 Active learning
- 💬 Language tasks
🏆 Contributing¶
We love your input! Please see our contributing guide to get started. Thank you 🙏 to all our contributors!
👩⚖️ License¶
The autodistill package is licensed under an Apache 2.0. Each Base or Target model plugin may use its own license corresponding with the license of its underlying model. Please refer to the license in each plugin repo for more information.
Frequently Asked Questions ❓¶
What causes the PytorchStreamReader failed reading zip archive: failed finding central directory error?¶
This error is caused when PyTorch cannot load the model weights for a model. Go into the ~/.cache/autodistill directory and delete the folder associated with the model you are trying to load. Then, run your code again. The model weights will be downloaded from scratch. Leave the installation process uninterrupted.
💻 explore more Roboflow open source projects¶
| Project | Description |
|---|---|
| supervision | General-purpose utilities for use in computer vision projects, from predictions filtering and display to object tracking to model evaluation. |
| Autodistill (this project) | Automatically label images for use in training computer vision models. |
| Inference | An easy-to-use, production-ready inference server for computer vision supporting deployment of many popular model architectures and fine-tuned models. |
| Notebooks | Tutorials for computer vision tasks, from training state-of-the-art models to tracking objects to counting objects in a zone. |
| Collect | Automated, intelligent data collection powered by CLIP. |